Predicción de fechas de prioridad en el Visa Bulletin de los Estados Unidos
Sistema predictivo aplicado para el panel multiserie indexado por país o área de cargabilidad × categoría migratoria × tipo de tabla × mes. Pronósticos a horizontes de 1, 3, 6 y 12 meses con intervalos de predicción al 95 %, bajo metodología CRISP-DM y validación walk-forward expansiva — sin privilegiar arquitecturas de antemano.
- Boletines mensuales
- 296
- Observaciones del panel
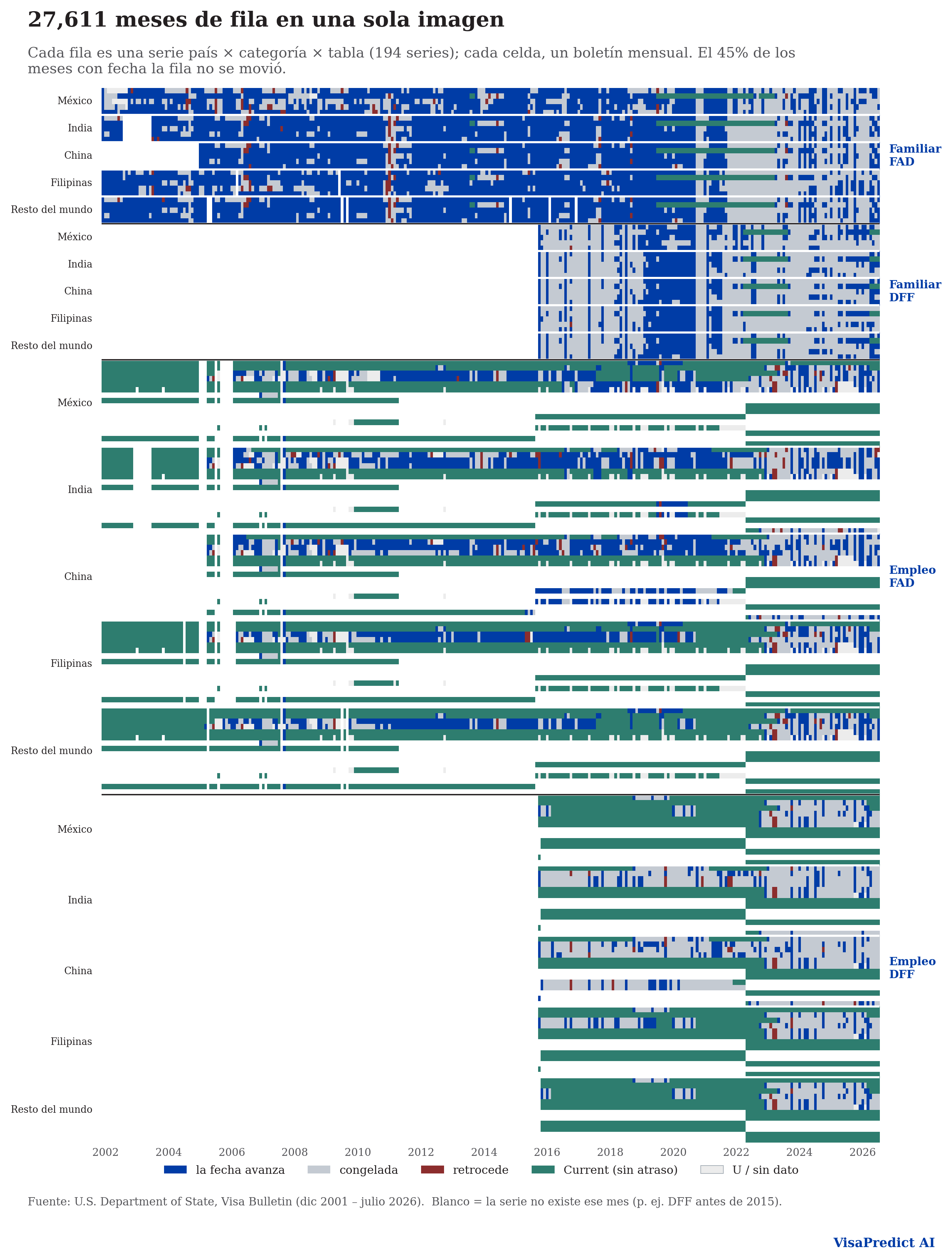
- 27,611
- Series país × categoría × tabla
- 194
- Países / áreas piloto
- 5
- Metodología nominada
- CRISP-DM
El problema, en una figura
Cada fila es una serie país × categoría × tabla y cada columna uno de los 296 boletines mensuales publicados desde diciembre de 2001: la fila avanza, se congela y a veces retrocede años en un solo boletín. Anticipar ese movimiento — con su incertidumbre — es el problema que este sistema ataca.

¿Cuándo me toca?
Elige tu país o área, categoría y tabla y mira el pronóstico del modelo desplegado a 12 meses, con bandas de predicción al 80 % / 95 %.
Ver el pronóstico de tu categoríaLa evidencia, contra la realidad
Cada pronóstico usa solo la información disponible hasta su origen y se califica contra el boletín real publicado (backfill sin fuga de información).
Ver el marcador prospectivoExplora el proyecto
El proyecto se divide para leerse con foco: el documento académico, la ingeniería de datos, los datos históricos interactivos, los recursos de consulta y el asistente.
Anteproyecto
El documento académico: introducción, marco teórico, producto, metodología CRISP-DM, tablas y reproducibilidad.
I · Introducción, II · Marco teórico, III · Producto y validación, IV · Metodología CRISP-DM, Tablas y figuras, Reproducibilidad02Ingeniería de datos
Cómo se construyó y entendió el panel: pipeline, análisis exploratorio, ingeniería de características, prácticas MLOps, estructura del repositorio y almacén en esquema estrella.
Construcción del panel, Análisis exploratorio, Ingeniería de características, Prácticas MLOps, Estructura del repo, Modelo de datos03Datos históricos
El corazón empírico: boletín en vivo, pronóstico por categoría, explorador interactivo del panel real y el marcador prospectivo del sistema.
Boletines en vivo, Pronóstico, Explorador histórico, Marcador prospectivo04Galería de pronósticos
Todas las series de pronóstico país × categoría × tabla en una galería filtrable: hojea por país o por categoría y abre cualquiera para ver el abanico completo con sus bandas al 80 % y 95 %.
Destacados, Por país, Por categoría05Recursos
Descargas reales del proyecto, glosario operativo y referencias IEEE del documento académico.
Descargas, Glosario, Referencias IEEE06Asistente
VisaBot: asistente conversacional con recuperación aumentada (RAG) sobre toda la documentación del proyecto, con respuestas citadas.
VisaBotVisión sintética del proyecto
El proyecto desarrollará un sistema predictivo aplicado para las fechas de prioridad del Visa Bulletin, organizado como panel multiserie indexado por país de cargabilidad, categoría migratoria y tipo de tabla, bajo la metodología CRISP-DM (Chapman et al. 2000). Se compararán empíricamente modelos lineales y no lineales sin privilegiar arquitecturas de antemano.
Pronóstico transparente del Visa Bulletin
El boletín mensual del Departamento de Estado de EE. UU. publica fechas de prioridad por país de cargabilidad y categoría migratoria. Más de tres décadas de datos públicos (1992–2026) sin modelos predictivos abiertos y sistemáticamente evaluados que reporten intervalos de predicción al 95 %. Cerca de 4 millones de personas aguardan una visa familiar [6], dentro de un rezago global de USCIS de 11.5 millones de casos para todos los formularios [4].
Panel multiserie yp,c,b,t
Cada celda combina un país o área de cargabilidad p, una categoría migratoria c, un tipo de tabla b (FAD o DFF) y un mes calendario t. La variable predicha es continua: días desde una fecha base. El sistema se entrena exclusivamente sobre observaciones con fecha específica; las celdas Current y Unavailable se conservan como anotación descriptiva.
Marco comparativo bajo CRISP-DM
Tres familias complementarias: lineales (naïve estacional, ARIMA, SARIMA, Prophet), no lineales locales (LSTM puro, ARIMA-LSTM) y globales/tabulares (DeepAR, XGBoost). Validación walk-forward expansiva con métricas escaladas (sMAPE, MASE, MAE, RMSE) e intervalos de predicción al 95 % por tres mecanismos (ARIMA analítico, MC dropout, predicción conforme).
Dataset, sistema y aplicación
(1) Base de datos longitudinal reproducible del Visa Bulletin 1992–2026 publicada bajo licencia abierta; (2) sistema predictivo reproducible con código y manifiestos de versiones; (3) aplicación de demostración académica con advertencias explícitas sobre el carácter informativo y no legal de las estimaciones.
Acerca del autor y del asesor
Tesista y director de tesis del proyecto MIAAD, Universidad Autónoma de Ciudad Juárez. El curso anfitrión "Anteproyecto de Innovación Tecnológica" es coordinado por el Dr. Gilberto Rivera Zárate.


Anteproyecto de Innovación Tecnológica · Maestría en Inteligencia Artificial y Analítica de Datos · UACJ · Periodo enero–mayo 2026 · Coordinación: Dr. Gilberto Rivera Zárate.
¿Interesado en el proyecto?
Consultas académicas, colaboración o intercambio bibliográfico.